Generators and the Sweet Syntactic Sugar of Coroutines

The Cambrian

Good Old Functions
Say we want to iterate over all the elements of a vector.
We can write a function - a.k.a. sub-routine - to do that:
void vectorate(std::vector<int> const& v)
{
for (auto e: v) // 1. iterate
std::cout << e << '\n'; // 2. do something: print e
}
If we want to draw a line on some image or device, then algorithms in books and resources will typically look something like this function (a simplified Bresenham variant):
void drawline(int x0, int y0, int x1, int y1) // Partial Bresenham
{
int dy=y1-y0;
int x=x0;
int y=y0;
int p=2*dy-dx;
while(x<x1) // 1. iterate
{
putpixel(x,y,7); // 2. do something: call putpixel()
if(p>=0)
{
y=y+1;
p=p+2*dy-2*dx;
}
else
{
p=p+2*dy;
}
x=x+1;
}
}
In both examples, the functions do two things:
- They iterate over a sequence, i.e. the vector or the pixel positions along a line;
- They do some operation with each of the sequence elements
If we wanted to sum the vector elements, we would need to re-write vectorate() to sum the elements instead of (or in addition to) printing them.
Similarly, drawline() assumes that a function putpixel():
- is available in scope (for compilation and linking);
- has the correct signature;
- will do the right thing when called;
- will actually return control to
drawline()for continued operation.
A larger issue here is that both functions are “closed” in the sense that they only return after they have iterated over the whole sequence. They eagerly process a whole sequence.
Callbacks
One common way to overcome some of these limitations is by passing external callback functions to our own functions. Some C++ mechanisms that allow this are function-pointers or using “Callable” template parameter types (or Concepts in C++20) for passing e.g. lambdas. This is exactly how predicates work in many STL algorithms for example.
A few well known problems with callbacks and callables are:
- Inversion-of-Control: Letting library code call external code that is not neccesarily trustworthy, valid or correct while still in mid-computation.
- Callback-Hell: Where program flow skips between many decoupled parts of the code that your code becomes extremely hard to understand, reason about and maintain (not to mention any potential performance issues).
- The functions are still eager and closed, requiring the creation/processing of the full sequence.
The concept of a function, or sub-routine goes back to one of the first computers, the ENIAC, in the late 1940s and the term sub-routine is from the early 1950s.
🤔
If only there was a way to “flip” these iterating functions “inside-out” and iterate over a sequence without pre-committing to, or having to specify a, specific operation…
Pre-History
🦖
Iterators
The concept of Iterators has been with C++ since the STL was designed by Alex Stepanov and together with the rest of the STL became part of C++98. They are a powerful abstraction for, well, “openly” iterating over elements of a sequence.
Two related concepts are Iterator Objects and Iterator Adaptors. These are “stand-alone” iterator types which are often only indirectly or implicitly coupled to a sequence. The C++ standard actually has quite a few of them, both old and new including, for example:
std::istream_iterator: a single-pass input iterator object that reads successive objects of typeTfrom thestd::basic_istreamobject for which it was constructed, by calling the appropriateoperator>>. The actual read operation is performed when the iterator is incremented, not when it is dereferenced. The first object is read when the iterator is constructed. Dereferencing only returns a copy of the most recently read object.std::reverse_iterator: an iterator adaptor that reverses the direction of a given iterator.std::recursive_directory_iterator: an iterator object that iterates over thedirectory_entryelements of a directory, and, recursively, over the entries of all subdirectories. Here the file system directory sub-tree hierarchy is the “sequence” and not an actual program object with elements (since C++17).- Interestingly, the functions
std::prev_permutation()andstd::next_permutation()are not iterators but do have some iterator-like behavior combined with mutating the underlying sequence.
A useful example of a user defined iterator object is OpenCV’s cv::LineIterator which is “used to iterate over all the pixels on the raster line segment connecting two specified points”. It has a typical iterator object type API (simplified for brevity):
class LineIterator
{
public:
// creates iterator for the line connecting pt1 and pt2 in img
// the 8-connected or 4-connected line will be clipped on the image boundaries
LineIterator( const Mat& img, Point pt1, Point pt2, int connectivity = 8);
uchar* operator *(); // returns pointer to the current pixel
LineIterator& operator ++(); // prefix increment operator (++it). shifts iterator to the next pixel
// public (!!!) members [ <groan 😩> ]
uchar* ptr;
const uchar* ptr0;
int step, elemSize;
int err, count;
int minusDelta, plusDelta;
int minusStep, plusStep;
};
This iterator does not have an explicit sequence to iterate over. Instead it lazily creates the elements of the sequence as the iterator is incremented (using various Bresenham variants).
cv::LineIterator gives us incremental access to all the pixels along a line in the image. We may draw the line by setting color values to the pixels, easily implementing e.g. line color gradients external to the iteration itself. Alternativly, we may sum the pixel values along the line or mix its value with some alpha channel. The possibilities are endless and need not be known to cv::LineIterator itself.
Objects that lazily generate values on demand are also known as Generators.
Here is a usage example from the docs:
cv::LineIterator it(img, pt1, pt2, 8);
std::vector<cv::Vec3b> buf(it.count);
for(int i = 0; i < it.count; ++i, ++it) // copy pixel values along the line into buf
buf[i] = *(const cv::Vec3b*)*it;
It externalizes the iteration to the user code.
Imperfect Abstraction
However, there still are a several abstraction-related problems with this code (horrible public members notwithstanding).
First, the iterator’s operator*() (i.e. *it in the snippet) returns a uchar* which must be cast to a pointer of the actual pixel type of the image. This is awkward and could be fixed by e.g. deriving a class template from cv::LineIterator when the image pixel type is known at compile time (similar to how cv::Mat_ is a template matrix class derived from cv::Mat.)
But this is a cv::LineIterator specific issue, so we will not dwell on it here.
There are more severe concerns which are, in fact, symptomatic for all iterator objects.
The Odd Couple
How do we know when to stop incrementing the iterator (e.g. ++it)?
How do we know the sequence is “done”?
This is a question all iterator objects must answer.
- For
cv::LineIteratorwe must make sure we iterate at mostit.counttimes. - For
std::istream_iterator, the default-constructedstd::istream_iteratoris known as the end-of-stream iterator. When a validstd::istream_iteratorreaches the end of the underlying stream, it becomes equal to the “universal” end-of-stream iterator. - A
std::reverse_iteratormust be compared to the corresponding sequence’srend()iterator. std::recursive_directory_iteratormust be compared to the value returned by calling the free functionstd::end()on it.
Note that the last two examples (std::reverse_iterator and std::recursive_directory_iterator) demonstrate one of the biggest drawbacks of the iterator abstraction: the end-iterator is tightly coupled, at run-time, to the begin-iterator creation object. This is a pitfall when the provided end iterator is of the correct type but not created from the same sequence. It is undefined behavior. The code will compile silently and if you’re really lucky you’ll get a crash (if not, nasal demons may ensue).
Ranges
Ranges are a more general concept than iterators. They are the answer to the problems of the Odd Coupling. By encapsulating a begin and end iterator-pair or e.g. an iterator + size (or iterator and some way to check a stopping condition) they allow creating a single object that makes the STL iterators and algorithms more powerful by making them composable. Once we have the Range abstraction, we can build range adaptors and build pipelines that transform ranges of values in interesting ways.
Ranges are coming to C++20 and are an amazing new addition to the standard library!
All the fabulous ranges we are getting are, in many ways, iterator objects and adaptors that provide the end-iterator in a standard mandated way (via std::end()). Their API is very similar to the APIs I presented above with the addition of support for std::begin() and std::end(). In fact, that’s why std::recursive_directory_iterator mentioned above is a Range.
I will not review the enormous power of ranges here. Instead, we’ll only contemplate how Ranges may be implemented, and how we can create our own.
However, since Ranges are generalized iterators, implementing them still suffers from another difficulty that plagues iterator implementations…
Distributed Logic
The iterator object cousin of Callback-Hell, is the iterator API requirement for distributed logic and centralized-state. While the iteration loop is abstracted away to the external user, intermediate iteration/computation variables are stored as (mutable) members, and iteration logic is split between the constructor and member methods like the increment operator++ (the indirection operator*() is usually trivial).
Let’s look at the implementation of cv::LineIterator:
//...
inline uchar* LineIterator::operator *() // trivial
{ return ptr; }
inline LineIterator& LineIterator::operator ++() // loop iteration logic
{
int mask = err < 0 ? -1 : 0;
err += minusDelta + (plusDelta & mask);
ptr += minusStep + (plusStep & mask);
return *this;
}
//...
After the constructor (not shown) sets up all the member variables, it is up to the user to iterate and increment the iterator via ++ at most .count times. The “current” pixel along the line is the one pointed to by .ptr.
Basically, the operator++() body is exactly the iterating for-loop body and where instead of performing some prescribed operation on the current element, the element is “returned” by updating the ptr member and returning *this to allow calling the indirection operator for actually accessing it.
To write [grok or debug] cv::LineIterator, one must write [read] the constructor, then the indirection operator and the increment operators (not to mention additional methods and operators like the post-increment operator).
Additionally, by storing all the intermediate data as persistent members in the object (even if they are not public), we do not take advantage of scoped definition and locality (i.e. all methods can access and modify them at any point in the computation), opening the door for potential bugs, performance issues and increased object sizes.
Contrast this to the serial clarity of reverting cv::LineIterator to a non-iterable, but serial, function similar to what we saw at the beginning. It would look something like this:
void processLine(const Mat& img, Point pt1, Point pt2,...)
{
// local variables (cv::LineIterator member variables)
uchar* ptr;
const uchar* ptr0;
int step, elemSize;
int err, count;
int minusDelta, plusDelta;
int minusStep, plusStep;
// initialize local variable (cv::LineIterator::LineIterator() ctor)
// ...
// Now draw the line
for(int i = 0; i < count; ++i) // the explicit loop
{
// calculate the next element (LineIterator::operator++())
int mask = err < 0 ? -1 : 0;
err += minusDelta + (plusDelta & mask);
ptr += minusStep + (plusStep & mask);
doSomething(ptr); // <<!!! ptr is the "current" element/pixel
}
}
🤔
If only there was a way to write a simple, serial, loop algorithm with locally scoped stack-based intermediate variables which is much easier to read, debug and reason about while still abstracting way the iteration…
Present Day
🛫
Coroutines
“Coroutines make it trivial to define your own ranges.”
— Eric Niebler, Lead author of the C++ Ranges proposal (edited for drama)
Hmmm… is that so?
But wait, what are coroutines?
From Boost.Coroutine2: A coroutine (coined by Melvin Conway in 1958!) is a function that can suspend execution to be resumed later. It allows suspending and resuming execution at certain locations and preserves the local state of execution and allows re-entering the subroutine more than once. In contrast to threads, which are pre-emptive, coroutine switches are cooperative: the programmer controls when a switch will happen. The kernel is not involved in the coroutine switches.
This sounds just like what we want!
If we made processLine() above a coroutine then, instead of calling doSomething(ptr) in the loop body, we could (somehow) suspend the execution and yield the current value ptr. When the user so indicates (somehow), we can resume the computation from where we left off!
🤯
To preserve state across calls, the coroutine local stack must persist beyond the initial call and unlike a regular [sub-]routine/function, after returning, the coroutine stack must persist and should not be overwritten as that is where the state is stored. Moreover, re-entry should resume from the suspension point where we left off in the previous call.
Amazingly, most common CPU architectures and OSs support multiple stack contexts for non-pre-emptive or cooperative threading via mechanisms called fibers (as opposed to the pre-emptive threads). The Boost.Coroutine2 library provides cross-platform abstractions over the various architectures and OSs (using Boost.Context for the low-level platform-dependent parts). [P0876R8] proposes adding fiber_context support to the standard library. We’ll see.
Intermezzo
A few years ago I wrote an algorithm that was easiest to implement and maintain when expressed as a coroutine generator. Boost.Coroutine2 provided a reasonable interface for writing coroutines and was quite usable. My algorithm was a great success and another project in the company decided to adopt it due to its superior performance. However, that project used emscripten to compile the C++ code to JavaScript.
Unfortunately, building Boost with emscripten was neigh impossible and specifically the platform dependent Boost.Context was not designed to be “ported” to JavaScript running in a browser. What is one to do?
After a lot of soul and web searching, and not wanting to manually distribute the complex algorithm logic into an iterator/Range API, I found that Boost.ASIO has a small, badly indexed, unnamed and well hidden “stackless” coroutine library. This single header file “library” is totally portable (maybe even C-compatible too). It also does not even depend on any other parts of Boost and can be easily used stand-alone (with minor edits). After some tweaking of my own (portable) algorithm code, the algorithm could compile and ran successfully as compiled client-side browser JavaScript.
So how does it this mysterious “ASIO.coroutine” work?
Chris Kohlhoff, the author of ASIO, describes it in a blog post from 2010: “A potted guide to stackless coroutines”. Go and read that post and prepare to have your mind blown. Using a clever combination of macros and switch statements, Kohlhoff manages to introduce new “pseudo-keywords” like yield that can be used for yielding values from a coroutine. 🤯
From the user side, declaring an ASIO.coroutine is quite simple (quoting the post):
Every coroutine needs to store its current state somewhere. For that we have a class called
coroutine. Coroutines are copy-constructible and assignable, and the space overhead is a singleint. They can be used as a base class:class session : coroutine { ... };or as a data member:
class session { ... coroutine coro_; };It doesn’t really matter as long as you maintain a copy of the object for as long as you want to keep the coroutine alive.
Using it to yield values:
The
yield return <expression>is often used in generators or coroutine-based parsers. For example, the function object:struct interleave : coroutine { istream& is1; istream& is2; char operator()(char c) { reenter (this) for (;;) { yield return is1.get(); yield return is2.get(); } } };defines a trivial coroutine that interleaves the characters from two input streams.
This type of yield divides into three logical steps:
yieldsaves the current state of the coroutine.- The resume point is defined immediately following the semicolon.
- The value of the expression is returned from the function.
An instance of the interleave class has an overloaded function call operator () and will yield interleaved chars, one by one, when called consecutively.
So the syntax is not perfect (note the reenter (this) above) but it is totally portable and it works great for generators. “ASIO.coroutine” does not require CPU/OS level fiber facilities and instead opts for managing the “stack” variables as an object body and the suspend/resume points via switch statement “markers”. (BTW, the idea is not new. See a similar C version going back to 2000)
Despite its coolness, we will not be using “ASIO.coroutine” because there is a new kid on the block!
The Future is Now
C++20 Coroutines
Coroutines will become a language level facility in the C++20 standard!
A C++20 function is a coroutine if its definition does any of the following:
- uses the
co_awaitoperator to suspend execution until resumed; - uses the keyword
co_yieldto suspend execution returning a value; - uses the keyword
co_returnto complete execution returning a value.
Every coroutine must have a return type that satisfies a number of requirements.
How do we know if a function is a coroutine?
We cannot.
Not from its signature at least. Only if its body uses any of the special keywords/operator can we determine if it is a coroutine (unless [P1485R0] Better keywords for the Coroutines TS has its way and we would need to decorate the function definition (though not the declaration) with a new context sensitive keyword async and also maybe drop the ugly co_ keyword prefixes, we’ll see - probably not for C++20). Sometimes, as in the case of generators, the function return type is an indicator that the function may be a coroutine (but it may just be returning the result of a coroutine as well).
Stacklessness and Stackfulness
C++20 coroutines suspend execution by returning to the caller and the data that is required to resume execution is stored separately from the caller-stack. Essentially, the coroutine-stack is not (generally) stored on the caller-stack (To make this even more confusing they are called Stackless-coroutines do distinguish them from Stackful-coroutines which use CPU/OS fibers)).
However, in many cases, especially with synchronous generators, the compiler, where possible, will elide the heap allocation for the coroutine-stack for the coroutine extra data and put it directly in the stack-frame of the calling function - making it a very cheap abstraction.
There is so much to say about C++20 coroutines and this blog post will only scratch the surface of the capabilities of this amazing new feature. So see it as an incentive to learn more. We will only look at coroutines from the narrow view of creating (synchronous) Generators or Ranges from the users perspective (as opposed to compiler writers or library implementors). Practically, this means we’ll only focus on using the co_yield keyword.
Show Me Some Code Already!
We’ll start with the simplest possible example:
auto zoro() { return 42; }
What does zoro() return? It returns 42.
Its return type is… int.
Easy Peasy.
Is it a coroutine? No.
auto coro() { co_yield 42; }
What does coro() return? It does not return 42.
What is its return type? It is not int.
Is it a coroutine? Yes.
How do we use it?
The coroutine coro() returns a generator in a suspended state which, when resumed, will yield the int value 42 (and no more values after that).
So how do we use it?
Like we use any iterator object.
auto gen = coro(); // the (suspended) generator
auto it = gen.begin(); // the iterator: resumes the coroutine, executing it until it encounters co_yield
cout << *it; // dereference to get the actual value.
// or alternatively
cout << *coro().begin();
Our generator is a range, so we can also put it in a range-for loop (which, in this case, will run just once):
for (auto v: coro())
cout << v;
Note that unlike std::istream_iteratorwhere the first object is read when the iterator is constructed, here the first value will only be ready after begin() is called and not upon construction.
That’s pretty amazing!
The compiler took our linear, serial code and created an object, a generator (std::generator<int>), breaking our code up into little pieces and taking care of all the hassle of choosing and selecting which of the local state variable must be saved as members (none in this trivial example), adding methods for increment operator support, indirection operator *, begin() and end() etc (it does this by collaborating and interoperating with the conforming return type).
If we thought C++11 lambdas were impressive Syntactic Sugar, this the Syntactic Steroids of full-blown code generation!
Reality Check
I lied. That code, though it does compile and work, is non-standard conforming and only a peek into the future. First, coroutines are not allowed to have anautoreturn type. This is only an MSVC feature that’s really great for explaining things. Upon encountering anautoreturn type (for aco_yieldusing coroutine), MSVC automatically infers it to bestd::experimental::generator<T>for the relevant typeT. Perhapsautoreturn types will be supported in a future standard but the reason it cannot be supported at the moment is:
There is no such standard classstd::generator<>!
The C++20 standard will not ship with any standard coroutine support library! What we are using here is Microsoft’s experimental implementation. This is a real shame, but a situation that is very high priority for the C++23 standard. There are several great open-source coroutine support libraries, most notably Lewis Baker’s fabulous cppcoro to fill this void in the standard.
For brevity, we’ll continue usingautoreturn type where its meaning is clear.
Obviously, single element ranges are rather boring.
Since coroutines are lazy we can easily generate infinite ranges:
auto iota(unsigned int n = 0)
{
while(true)
co_yield n++;
}
// usage:
std::copy_n(iota(42).begin(), 9, std::ostream_iterator<int>(std::cout, ","));
// prints: 42,43,44,45,46,47,48,49,50
The infinite loop will suspend at every iteration, yielding the current value, and only resume on demand (note that when eventually hitting max unsigned int it will wrap around (which is better than UB) so it is still an infinite loop).
To get a better feel for them, let’s take coroutines for spin.
Spin Cycle
Given a bunch of scattered pixels in an image, I once needed process the neighborhood around each pixel only up to the its closest neighbor. My solution was to scan the image in an ever growing (square) spiral around each pixel until bumping into the first neighbor.

Here’s a spiral generator around (0,0):
auto spiral()
{
int x = 0, y = 0;
while (true)
{
co_yield Point{ x, y }; // yield the current position on the spiral
if (abs(x) <= abs(y) && (x != y || x >= 0))
x += ((y >= 0) ? 1 : -1);
else
y += ((x >= 0) ? -1 : 1);
}
}
This code is image independent and will lazily spiral to infinity. Understanding the code logic is left as an exercise to the curious reader, but note that all the logic is in one, single, serial function, easy to read and debug. Figuring it out when distributed among multiple object methods would make the task significantly harder.
I mentioned line color gradients external to the iteration itself above. Let’s create an RGB color generator that infinitely cycles through the values of the Hue channel in the HSV color space to generate smoothly varying bright colors. We’ll use OpenCV to do the color conversions.
auto hueCycleGen(int step = 1)
{
Mat3b rgb(1,1), hsv(1,1);
hsv(0,0) = { 0, 255, 255 }; // { Hue=0, Full Saturation, Full Intensity }
while (true)
{
cvtColor(hsv, rgb, COLOR_HSV2RGB_FULL);
co_yield rgb(0,0); // yield the current RGB corresponding to the current HSV.
(hsv(0,0)[0] += step) %= 255; // cycle the H channel
}
}
We create two single pixel images, and infinitely cycle through the Hue channel values, converting the HSV color to RGB for display.
To draw the animation above, all that’s left to do is create the generators and lazily iterate them, in tandem. Can we use a single range-for loop to do this?
How do we iterate both generators in tandem with a single for loop?
Let’s zip them together!
template <typename T, typename U>
auto zip(T vals1, U vals2)
{
auto it1 = vals1.begin();
auto it2 = vals2.begin();
for (; vals1.end() != it1 && vals2.end() != it2; ++it1, ++it2)
co_yield std::make_pair(*it1, *it2);
};
Yes! Coroutines may be templates too!
zip() takes two generators, gets their begin() iterators and walks them in tandem until either one is done (if ever). It lazily yields a std::pair of their yielded values.
Note that the ranges-v3 library has a much more powerful zip “view” that should work similarly to this simple and naive version (remember that coroutine generators are Ranges), though AFAIK it is not part of the Ranges library that was accepted into the C++20 standard. We will most likely be getting more Range views and actions in C++23.
We can now compose them together in a range-for loop with C++17 structured bindings:
for (auto [pos, color] : zip(spiral(), hueCycleGen())) // 1. zip the generators
{
cv::Point pix = pos + offset; // 2. offset to actual pixel position
if (img.rows*2 <= pix.x && img.cols*2 <= pix.y) // 3. no more pixels to scan
break;
if (!rect.contains(pix)) // 4. skip out of bounds
continue;
img(pix) = color; // 5. set pixel color
}
We’re creating a single generator from two and iterating them in tandem. How cool is that?
Since coroutine generators are Ranges, they should be able to compose with many of the Range (and range-v3) views, adaptors and actions. Examples of this will have to wait for a future post.
Here’s another version with the Hue cycle 10 times as fast (hueCycleGen(10)):

Looking at zip(), we might want to make sure it is called with actual generators and not just any T and U. We could use template meta-programming tools to do that but, hey, this is C++20! We have Concepts! Feel free to try it!
Also, zip() seems very specific. Why limit ourselves to just two input generic generators? What not support zipping together of any number of generators?
Well, coroutines templates also support variadic arguments. If you need that functionality, check out ranges::views::zip.
Working with Structs-of-Arrays (instead of Arrays-of-Structs) is common in game and graphics programming. Zipping ranges together on the fly like this may make SoA programming more convenient and expressive.
As we saw, coroutines can take other coroutines are arguments and process them. We can easily create filters, conversions and many other views and actions similar to what any Ranges library provides.
Python’s itertools library provides functions creating iterators for efficient looping. I urge you to go look at the itertools documentation. The equivalent C++ version basically writes itself in an almost one-to-one mapping.
Tree Traversal
Say we have a binary tree and we’d like to iterate over it’s nodes.
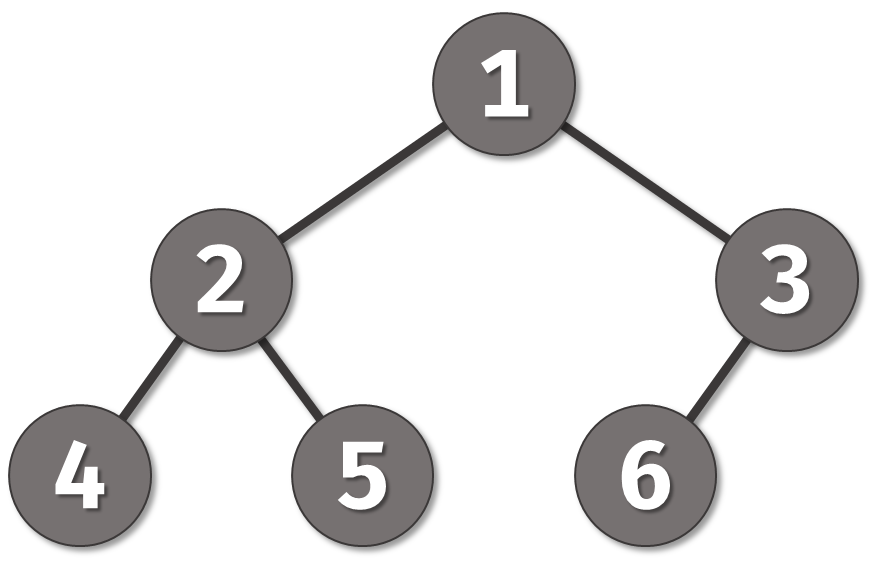
We may write something like this:
class TreeNode
{
// ...
using ValueGen = std::experimental::generator<int>;
ValueGen inorder() // In-order (Left, Root, Right)
{
if (left_)
for (auto v : left_->inorder()) // iterate on recursion
co_yield v;
co_yield val_;
if (right_)
for (auto v : right_->inorder())
co_yield v;
}
ValueGen preorder() // Pre-order (Root, Left, Right)
{
co_yield val_;
if (left_)
for (auto v : left_->preorder())
co_yield v;
if (right_)
for (auto v : right_->preorder())
co_yield v;
}
ValueGen postorder() // Post-order (Left, Right, Root)
{ /* ... */ }
enum Order { IN_ORDER, PRE_ORDER, POST_ORDER };
auto order(Order order) // this is NOT a coroutine!
{
switch (order)
{
case IN_ORDER: return inorder();
case PRE_ORDER: return preorder();
case POST_ORDER: return postorder();
}
}
Here we have three class methods (inorder(), preorder() and postorder()) that are in fact coroutines, and one regular, non-coroutine method, order(), returning a coroutine generator.
Each traversal function, recursively traverses the child nodes, co_yielding they “yielded” values. Given a TreeNode head, we can iterate over the tree elements in an chosen order e.g.:
for (auto val : head.order(TreeNode::IN_ORDER))
std::cout << val << ", ";
Will print 4, 2, 5, 1, 6, 3,.
The cppcoro library provides an even more convenient alterative: recursive_generator<T>. It is similar to a generator except that it is designed to more efficiently support yielding the elements of a nested sequence as elements of an outer sequence. In addition to being able to co_yield a value of type T you can also co_yield a value of type recursive_generator<T>. So when you co_yield a recursive_generator<T> value, all elements of the yielded generator are yielded as elements of the current generator.
This simplifies the code above as there is no need for the internal range-for loops. The coroutine methods will look something like this:
cppcoro::recursive_generator<int> inorder() // Inorder (Left, Root, Right)
{
if (left_) co_yield left_->inorder();
co_yield val_;
if (right_) co_yield right_->inorder();
}
An recursive traversal function can’t get much simpler than that!

(Of course we could have traversed the tree without recursion, but where’s the fun in that?)
Further Discussion
The centralization of logic afforded by coroutines becomes more and more beneficial as the coroutine logic becomes more complex. The more co_yields we have, the more nested loops and logical algorithmic sections we have, the more difficult and unwieldy it would become to implement, debug and maintain as a lazy iterator without coroutines. I am a big fan of early return code flow and this style is perfect for early co_yield (which, again, is difficult to maintain correctly with manually managed state information).
Another interesting use case that comes to mind: Given a serial function, e.g. sort, insertion of carefully placed single line co_yields allows us to “X-Ray” the function (which is now a coroutine), in mid-computation, for debugging and/or visualization purposes without changing the logical layout of the code. This is win for insight and code visibility (and not so different from what we did in the spiral example above). Perhaps in production the co_yields may be removed and the coroutine reverts to a regular subroutine (i.e. function).
I’m actually speculating here so I’d love to hear your thoughts on the matter in the comments below.
Advanced Features
We use co_yield to yield a value to the caller and suspend execution. However co_yield out is an expression and resuming resumes from there. Since it is an expression and not a statement, it has a value (and a type) and could be used like this auto in = co_yield out;. The type of the co_yield out expression is not (neccesarily) the type of the yielded value! When properly customized (i.e. in the coroutine return value type) it is possible to resume with some value from the resumer/caller which may be of a different type from the yielded value! This means we can pass data back into the currently executing coroutine and potentially affect its behavior from the resume point! I think this is mind-blowing stuff! 🤯
As of this writing, I am not aware of any generator type that makes use of this feature, but Lewis Baker suggested an very “obvious”, slap-your-forehead-why-didn’t-I-think-of-that, use case:
One example use for this that I had was implementing a cursor-like generator with a random-access advance operation. I.e. that allowed you to expose an iterator with
--,+= n,-= nthat would resume fromco_yieldwith theptrdiff_tincrement value. You could write a generator type that allowed you to seek within the sequence. For example:
iterator::operator++()would causeco_yieldexpression to return+1.
iterator::operator+=(difference_type d)would causeco_yieldexpression to return the delta,d. It could then do an efficient random access of the range.
This is very cool and shows that there is still a lot of room for innovation and that the underlying language support is generic enough to allow such advanced usage.
Traps
Dangling References
Coroutine execution starts only after calling begin() for the first time. This can lead to what is known as the Dangling Reference problem of coroutines.
This code seems reasonable (taken from Arthur O’Dwyer’s blog post):
generator<char> explode(const std::string& s)
{
for (char ch : s)
co_yield ch;
}
int main()
{
for (char ch : explode("hello world"))
std::cout << ch << '\n';
}
Run it here. From the post:
See, in C++2a-Coroutine-world, the function
explode()isn’t really one indivisible routine. It’s a coroutine, which means it gets split up by the compiler into a bunch of little code fragments — with the divisions between fragments coming at so-called “suspend points” — and the only way these fragments communicate with each other is via state stored in the coroutine frame.What state is stored in
explode’s coroutine frame? Well, it needsch(or let’s pretend it does for the sake of this example); and it needss. What’s the type ofs?sis aconst std::string&. It’s a reference to the temporary string created on line 1 ofmain(). And when does that string die? Also on line 1 ofmain()! So the reference captured intoexplode’s coroutine frame is dangling as soon asexplodehits its first suspend point.
Ouch! See the rest of the post for more examples of this and some opinionated commentary on the subject.
⚠️ Be vewy vewy caweful passing tempowawy values to cowoutines.
If you expect the user to pass temporaries you must take the parameters as copies i.e. pass by value.
(I am not an expert on this, so if there is better advice to ping me and I will update it here with due credit).
Decapitation
Let’s say we need to parse a file encoded in one of multiple supported format versions (e.g. for backward and forward compatibility) and we have coroutines to parse each of the supported formats. We want to create a generator “factory” function that returns a single, format agnostic, generator to the user.
We’ll want to run the first supported format coroutine and check if the returned generator range is empty. If it isn’t empty, then we return the non-empty generator to the user. If it is empty, then we can create a new generator for the next supported format version.
Checking for emptiness requires comparing begin() to end(). However, remember that a generator begins execution once begin() is called and will run until the first suspension point. If the generator is actually empty, we can, indeed, continue as planned and try a different coroutine. In the case when the generator is not empty, the generator is now in a suspended state with the first generated value available. If we now return it (the generator object) to the caller, the caller, unwittingly, will call begin() again (as one does with generators) which, unless otherwise implemented, will resume execution and the first value will be skipped, the user unaware that it was ever missing. More often that not this decapitation will happen, and in general there is no guarantee that begin() is in any way idempotent.
We have to be careful passing around generators in an initially suspended (pre-execution) state. Do not use an empty range (i.e. generator) to indicate error since checking for emptiness sets its execution in motion and decapitation may ensue [1].
To indicate generator creation failure, I came up with this approach:
optional<generator<int>> maybeGen(bool fail)
{
if (fail) return std::nullopt; // oops, no generator
return [](){ co_yield 42; }(); // immediately invoked lambda coroutine expression
}
Here, maybeGen() is not a coroutine, but a regular function returning an optional generator. If and when conditions allow, it returns a valid (initially suspended) generator by immediately invoking an internal lambda coroutine to create the actual generator.
Now, an external function may check the optional and return the contents if it is valid without resuming the generator execution.
⚠️ This is not a panacea since pre-coroutine validity check(s), must be made outside the internal lambda. There is no way for the internal coroutine-lambda to communicate pre-parsing failure to
maybeGen()since it only starts executing aftermaybeGen()already completes execution and goes out of scope. Any local variables thatmaybeGen()could have sent the lambda e.g. via arguments or captures, will be dangling references if the lambda tries to access or modify them.
🧟
⚠️ Manipulating coroutines in an initially suspended state, are like a black mirror opposites of “zombie” moved-from objects. You must be very careful not to inadvertently set them off.
🧟♀️
Limitations
Coroutines are new. They are hot off the presses. They are not perfect. They are not complete (in many senses of the word).
Though coroutines may be templates and lambdas, as defined in the C++20 standard, coroutines cannot use plain return statements (though some current compiler implementations do still allow it), or placeholder return types (auto or Concept). Also, constexpr functions, constructors, destructors, and the main function cannot be coroutines. I suspect that at least some of these limitations will be lifted as we gain more experience, and as diligent developers like you, dear reader, write up proposals for extended features (lambdas also become incrementally more and more powerful from C++11, 14, 17 and 20).
Beyond these current language limitations, the main issue is the lack of standard library support. As mentioned above, there is no std::generator<> or any other coroutine support library type. All we have at this time is a detailed definition of the very low level facilities such types must expose and how the compiler code generation will interact with them.
This means that there is no standard definition for any generator type. For example, Microsoft’s implementation does not support yielding references generator<T&> while cppcoro::generator<T&> does (but using std::generator<std::reference_wrapper<T>> gets around this). This is actually very useful for yielding locally coroutine defined objects without copying or moving them. There is a problem of Quality-of-Implementation.
Coroutines and the various library implementations involve a lot of code generation and compiler optimizations currently suffer from Quality-of-Implementation issues as well. Some compilers will elide the heap allocations where other will not. I expect these large disparities to decrease once more compilers strive for competitive conformance.
Caveats
This is a motivational and introductory post about generators. It focuses on how to write generators and generator ranges from a coroutine user point of view. However, there are many other details in the presented building blocks it does not go into at all:
- It does not do justice to the elegance, beauty and richness of C++ Ranges and to how coroutines interop with them.
- It ignores many aspects of coroutines including how the compiler generates this magic, how to write low-level coroutine (library) types, asynchronous coroutines with the
co_awaitkeyword and many other wonderful features.
Resources
Here is a very partial list of resources (beyond those linked in the post) for learning more about this fascinating subject:
- Coroutines on
cppreference.com - A massive, well maintained, list of resources, papers, articles and videos from the diligent MattPD.
- You can find almost everyone involved in coroutine design and critique on the
#coroutineschannel on Slack. - Coroutines in C by Simon Tatham, 2000
- Multiple video versions of this post as a conference talk may be found online: NDC TechTown 2019, CppCon 2019, C++ Russia 2019 Piter, code::dive 2019, CoreHard Autumn 2019.
Credits
{kind=link}
-
Though this could be avoided with a suitable implementations of
generator<T>. This is a QoI issue, as generators are not yet in the standard library. ↩